Projects
The team develops a number of projects as proof-of-concept software. From the original research effort started in 1994, aimed at parallelism extraction from sequential source code, or program transformations to express parallelism, our research portfolio has evolved to accommodate the evolution of the High Performance Computing and Distributed Computing.
VMAD
VMAD stands for Virtual Machine for Advanced Dynamic analysis and transformation. This framework allows a user to mark in a source code some nested loops of any kind (for, while or do-while loops) in order to be handled by a speculative parallelization process and take advantage of the underlying multi-core processor architecture. It is composed of two main parts. First, extensions to the CLANG-LLVM compiler are devoted to prepare the program for being handled by the runtime system by generating different parallel versions. The second part takes place during the execution. The runtime system orchestrates then the launch of the different versions through a mechanism of sliding windows. Each target loop nest is run as a sequence of slices of the outermost loop. Each of these slices is run by using one of the versions generated at compile-time.
See dedicated site for more information : http://team.inria.fr/camus/vmad/
PolyLib
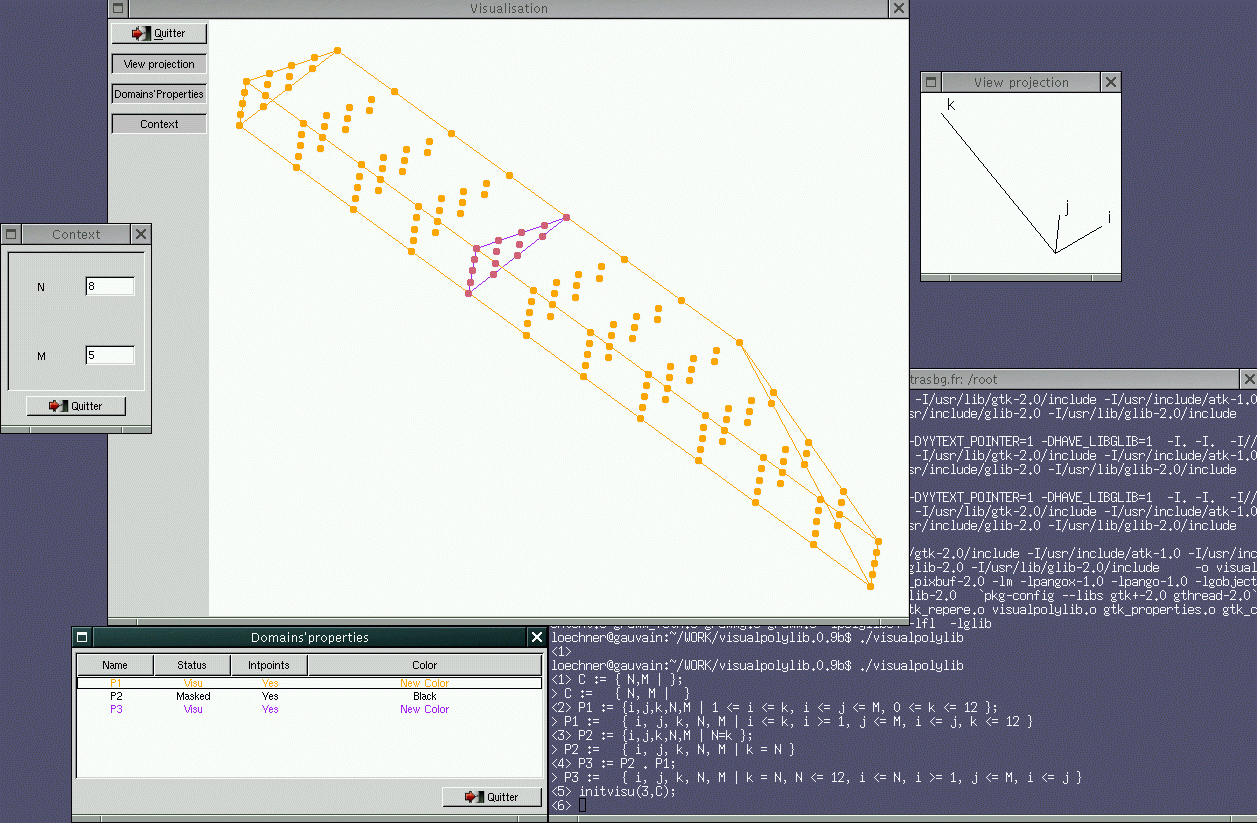
The Polyhedral Library (PolyLib for short) operates on objects made up of unions of polyhedra of any dimension. It was first developed by Doran Wilde at IRISA, in Rennes, France, in connection with the ALPHA project. This first version (1.1) manipulates non parameterized unions of polyhedra through the following operations: intersection, difference, union, convex hull, simplify, image and preimage, plus some input and output functions. The polyhedra are computed in their dual implicit and Minkowski representations, in homogeneous spaces.
Version 2 of the PolyLib included parameterized vertices computation. PolyLib3.14 includes Ehrhart polynomials computation, which permits to count the number of integer points contained in a parameterized polyhedron. PolyLib4 included the GNU MP library (as a compilation option), and 64 bits computations, in order to avoid integer overflows. Polylib5 is a merge of Strasbourg, Rennes and BYU Polylib.
See dedicated site for more information : http://icps.u-strasbg.fr/polylib
Nested Loop Recognition
We have developed a program implementing our loop-nest recognition algorithm, detailed in this paper. This standalone, filter-like application takes as input a raw trace and builds a sequence of loop nests that, when executed, reproduce the trace. It is also able to predict forthcoming values at an arbitrary distance in the future. Its simple, text-based input format makes it applicable to all kinds of data. These data can take the form of simple numeric values, or have more elaborate structure, and can include symbols. The program is written is standard ANSI C. The code can also be used as a library. We have used this code to evaluate the compression potential of loop nest recognition on memory address traces, with very good results. We have also shown that the predictive power of our model is competitive with other models on average. The software is available upon request to anybody interested in trying to apply loop nest recognition. It has been distributed to a dozen of colleagues around the world. We plan on using this software as the base for a new tool we currently design, for the analysis of parallel traces.
P2P-MPI
P2P-MPI is both an MPJ implementation and a middleware for the management of computing resources. Similar to the idea of sharing files through a P2P system, P2P-MPI lets its users share their CPU and access others’ CPUs. P2P-MPI is oriented to desktop grids: it is runnable as a simple user (no root privilege needed) and provides a transparent mechanism for fault-tolerance through replication of processes.
See dedicated site for more information : http://www.p2pmpi.org
Schlouder

Schlouder is a client-side broker of IaaS cloud resources.
Schlouder provides a user interface very similar to any batch-scheduler to submit a job to cloud-based platforms. Schlouder can manage a set of submissions according to different policies, which may favor speed of completion or cost of the computations. In the context of several clouds, jobs may be directed to one or several resource providers. In order to help the user choose the strategy which best matches his/her needs, Schlouder can also provide a prediction of the submission execution plan given the chosen strategy. This prediction is obtained through a simulation, which is based on the SimGrid toolkit.
Schlouder uses Slurm as batch-scheduler and either OpenStack or Eucalyptus as cloud kit.
See dedicated site for more information: http://schlouder.gforge.inria.fr
WAVE

{kind=link}
WAVE is an experimental parallel programming language. It forces a programmer to think differently. One could say that it is "topological" because a WAVE program makes explicit how data are organized. The Fibonacci series writes 0;1{;+} in WAVE.
See dedicated site for more information: http://wave.gforge.inria.fr